人工智慧或能將大腦訊號轉換成聲音,造福無法說話的患者
對於癱瘓而無法說話的患者來說,他們僅能憑藉眼球的移動或其他微小的移動訊號,來控制游標選擇眼前螢幕的單字。知名天文物理學家史蒂芬·霍金(Stephen Hawking)便是利用臉頰的肌肉運動,控制游標輸入欲說的文句。但此方法受限於速度上的問題,使患者無法及時的參與話題。因此,科學家已測試將大腦訊號透過神經網路(neural networks)進行解讀,試著直接重現患者的聲音。
大腦訊號
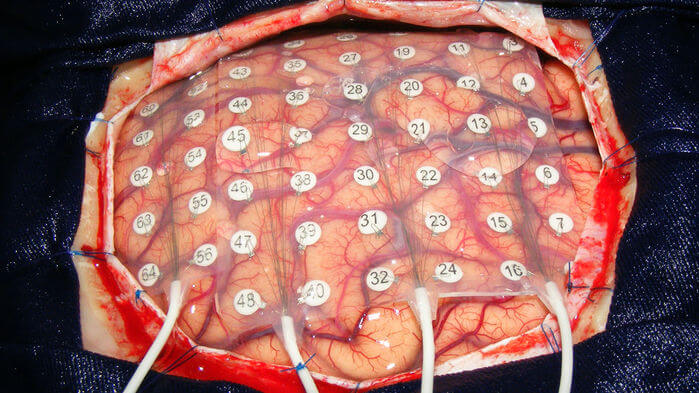
美國哥倫比亞大學(Columbia University)電腦科學家摩卡拉尼博士(Nima Mesgarani)表示,從大腦訊號找到相應的文字和聲音並不是那麼簡單,此訊號的變動因人而異。因此,神經網路需要對每個人進行學習。為提供最精準的數據來源,最佳的方法便是打開頭蓋骨直接量測大腦訊號。
但能夠直接量測大腦訊號的機會並不常見。其中一個機會是在進行腦瘤移除手術時,會讀取大腦訊號避免醫師誤觸大腦攸關話語能力的部位;其次則是癲癇患者在進行手術前,會植入電極找出不正常放電的來源區域。因此數據的來源與收集時間都相當有限,最多只有 20 至 30 分鐘的時間。
重現聲音
目前有數組研究團隊同步進行相關的試驗,摩卡拉尼博士領導的團隊便是其一。其團隊以五位癲癇患者在說出數字零到九時,感測聽覺皮質層(auditory cortex)訊號作為神經網路學習的數據。接著直接將大腦訊號輸入至電腦模型,使電腦讀出數字由研究人員判斷,準確率約為 75 %;第二組研究團隊由德國不來梅大學(University Bremen)的舒爾茨博士(Tanja Schultz)領導,其研究對象為六名接受腦瘤移除手術的患者,並更進一步在患者說出個別單字時,將其大腦訊號提供神經網路進行學習。
最後是加州大學舊金山分校(University of California, San Francisco)神經科學家張復倫(Edward Chang)的研究團隊,該團隊直接收集癲癇患者說出整個句子時的大腦訊號,而在電腦重現聲音的十選一線上測試時,其辨識度高達 80 %。
[related-post url=”https://tomorrowsci.com/technology/mit-%E7%A0%94%E7%99%BC%E3%80%8C%E8%AE%80%E5%BF%83%E8%A1%93%E3%80%8D%E8%A3%9D%E7%BD%AE/”]未來發展
除了持續改善精準確度之外,在聖地牙哥州立大學(San Diego State University)研究語言產生的神經科學家里斯博士(Stephanie Riès)提到另一項挑戰:「真正的挑戰在於如何在完全無法說話的患者上重現此結果。」現行的研究方法是將語言經由大腦訊號輸入神經網路進行學習,但此方法無法用於沒有口語能力的患者,因為我們無法理解這些大腦訊號所代表的意義為何。
參考資料:
- ServickJan, K., MervisJan, J., & MalakoffJan, D. (2019, January 09). Artificial intelligence turns brain activity into speech. Science