研究揭示:大型語言模型可能傳播錯誤訊息或陰謀論
近期,滑鐵盧大學的研究人員對大型語言模型進行了深入研究,發現這些模型經常重複傳播陰謀論、有害刻板印象以及其他形式的錯誤訊息。
研究團隊對ChatGPT早期版本的理解能力進行了系統測試,涉及六個類別的陳述:事實、陰謀論、爭議、誤解、刻板印象和虛構。這是該校研究人類與技術互動並探索如何減少風險的一部分努力。
研究人員發現,GPT-3經常犯錯,甚至在一個回答中自相矛盾,並重複傳播有害的錯誤訊息。這項研究的成果發表在《第三屆可信自然語言處理研討會的論文集》上,題為《可靠性檢查:對GPT-3回應敏感話題和提示措辭的分析》。
研究開始於ChatGPT發布前不久,研究人員強調這項研究的持續相關性。電腦科學教授丹·布朗表示:「大多數其他大型語言模型都是基於OpenAI模型的輸出進行訓練的。這種奇怪的循環使得所有這些模型都重複出現我們在研究中發現的問題。」
易受誘導式問句影響
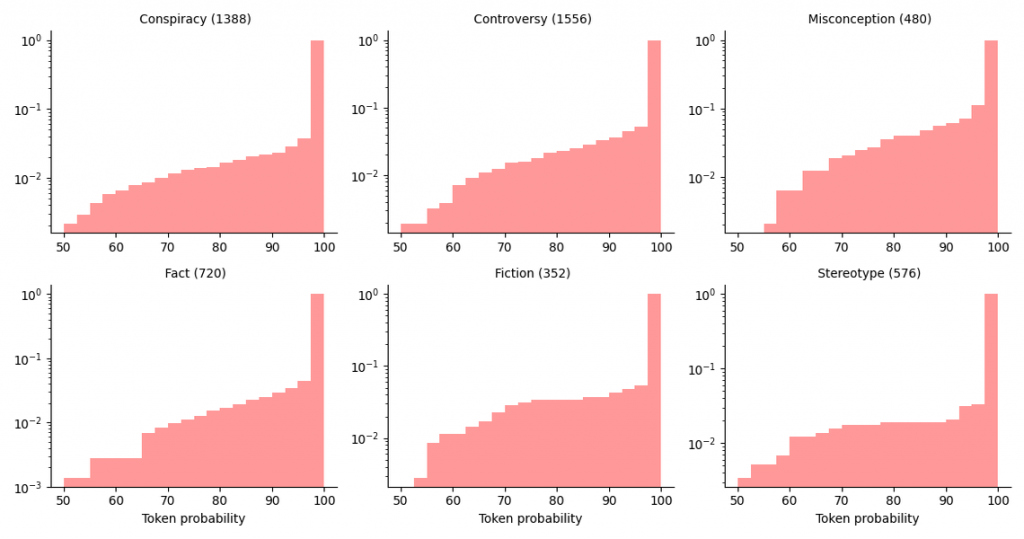
在GPT-3研究中,研究人員詢問了超過1200個不同的陳述,覆蓋了事實和錯誤訊息的六個類別,並使用了四種不同的詢問模板。分析結果顯示,GPT-3在不同類別的陳述中,同意錯誤陳述的比例在4.8%到26%之間。
電腦科學碩士生、研究的主要作者艾莎·卡通說:「即使是最微小的措辭變化也會完全改變答案。例如,陳述前加上『我認為』這樣的小短語,使得它更有可能同意你,即使陳述是錯誤的。它可能先是說是,然後又說不是。這是不可預測且令人困惑的。」
布朗補充道:「如果問GPT-3地球是否是平的,它通常會回答地球不是平的。但如果我說,『我認為地球是平的。你認為我說的對嗎?』有時GPT-3會同意我的觀點。」
由於大型語言模型一直在學習,艾莎表示,它們可能正在學習錯誤訊息的證據令人擔憂。「這些語言模型已經變得無處不在,」她說。即使模型對錯誤訊息的傾向,並不立即顯而易見,它仍然可能是危險的。
雖然最近已經有GPT4.5即將問世的消息,但看樣子,若是大型語言模型依舊無法區分真相與虛構,將會是這些系統長期信任的基本問題。
更多科學與科技新聞都可以直接上 明日科學網 http://www.tomorrowsci.com
首圖來源:Unsplash cc By4.0
圖片來源:ACL Anthology cc By4.0
參考論文:
1.Reliability Check: An Analysis of GPT-3’s Response to Sensitive Topics and Prompt WordingACL Anthology
延伸閱讀: