AI在「創意測試」中勝過人類:揭示未來創造力的新可能
在一項由阿肯色大學主導的創新研究中,151名參與者與ChatGPT-4進行了創意潛力的標準化測試對決。這些測試旨在評估發散性思維,這種思維方式被認為是創造力的重要指標。
發散性思維的特點是能夠為沒有固定答案的問題生成獨特的解決方案。例如,面對問題「如何避免與父母談論政治?」時,GPT-4提供了比人類參與者更獨創且詳細的答案。
研究名為《人工智能生成語言模型在發散思維任務上,比人類更有創造力的當前狀態》,由阿肯色大學心理科學博士生肯特·休伯特和金··阿瓦,以及心理科學助理教授及創意認知與注意力實驗室主任達里亞·札貝利娜撰寫,並發表於《科學報告》期刊。
研究採用了三種測試:替代用途任務(要求參與者為日常物品如繩子或叉子,想出創意用途)、後果任務(邀請參與者想像假設情況的可能結果,例如「如果人類不再需要睡眠會怎樣?」)以及發散聯想任務(要求參與者生成盡可能語義距離遠的10個名詞)。例如,「狗」和「貓」之間的語義距離不大,而「貓」和「本體論」之間則相差甚遠。
與人類不同,AI沒有主動性
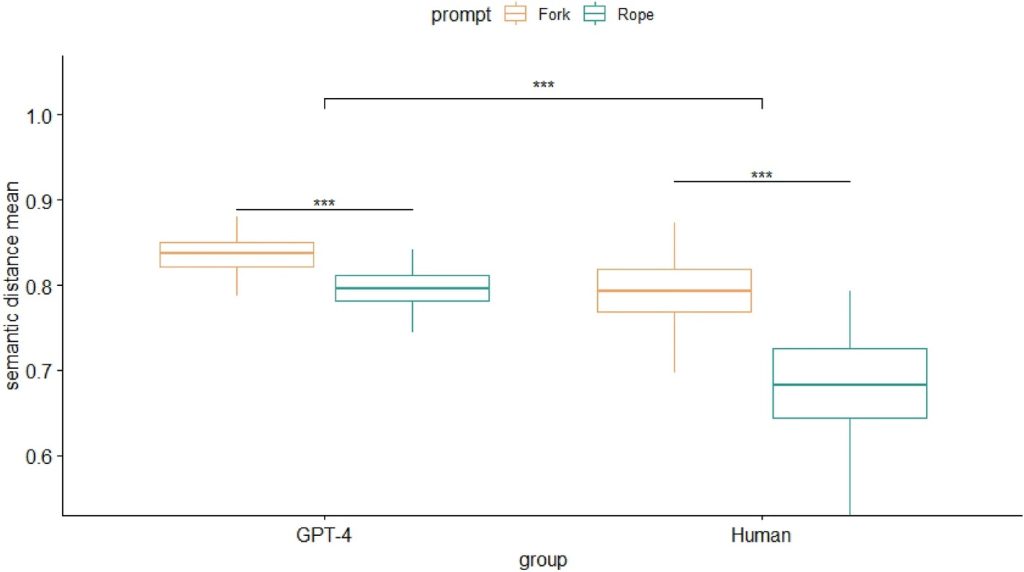
答案評估依據包括回應數量、回應長度和單詞間的語義差異。最終,作者發現「總的來說,即使控制了回應的流暢度,GPT-4在每個發散思維任務上都比人類更具原創性和詳細性。換句話說,GPT-4在整套發散思維任務中展現了更高的創造潛力。」
這一發現有些限制。作者指出「需要注意的是,本研究使用的測量都是創造潛力的測量,而參與創意活動或成就,是衡量一個人創造力的另一方面。」研究的目的是考察人類的創造潛力,而不一定是那些已建立創造憑證的人。休伯特和阿瓦進一步指出「與人類不同,AI沒有主動性」並且「依賴於人類用戶的幫助。因此,AI的創造潛力處於不斷的停滯狀態,除非被提示。」
此外,研究者並未評估GPT-4回應的適當性。因此,雖然AI可能提供了更多回應和更原創的回應,但人類參與者可能會覺得他們的回應需要基於現實世界的限制。
阿瓦也承認,人類撰寫詳盡答案的動機可能不高,並表示有關「如何對創造力進行操作化定義?我們真的可以說使用這些測試對人類是普遍適用的嗎?它是否評估了廣泛的創意思維?」的問題。這些測試是否完美衡量人類創造潛力並不是真正的重點。重點是大型語言模型正在迅速進步,並以前所未有的方式超越人類。它們是否會威脅到取代人類創造力還有待觀察。
目前,作者們繼續看到「展望未來,AI作為靈感工具,作為一個人創作過程中的輔助,或用於克服固定思維的可能性是有希望的。」
這項研究刊登在最新一期的《科學報告》。
更多科學與科技新聞都可以直接上 明日科學網 http://www.tomorrowsci.com
首圖來源:DALL.E
圖片來源:Scientific Reports cc By4.0
參考論文:
1.The current state of artificial intelligence generative language models is more creative than humans on divergent thinking tasks
延伸閱讀: