AI誇大科學研究結論達七成:新版模型反更不準確
最新研究指出,當前主流的大型語言模型(LLMs),如 ChatGPT 與 DeepSeek,在撰寫科學研究摘要時,經常誇大原始研究的結論。這項由荷蘭烏特勒支大學(Utrecht University)與加拿大西安大略大學及英國劍橋大學學者共同進行的研究,分析了近 5,000 則由 AI 所生成的科學摘要,結果顯示,高達 73% 的摘要內容存在程度不一的過度延伸,甚至產生誤導性的陳述。
這些誇大表現多為微妙但關鍵的語言改動,例如將「此研究中治療有效」轉述為「該治療有效」,從而讓讀者誤以為結果具更廣泛的適用性。研究涵蓋 ChatGPT、DeepSeek、Claude、LLaMA 等十款主流模型,並從《Nature》、《Science》、《The Lancet》等期刊的研究摘要與原文進行比對。
令人驚訝的是,當研究者在提示語中要求模型「避免不準確」時,反而更容易生成誇大的結論。與未加提示的情況相比,誇大比例幾乎增加一倍。研究作者之一 Uwe Peters 指出:「這項結果令人憂心。許多學生與決策者可能會以為要求 AI 更準確能提高可靠性,實際上卻適得其反。」
提示語說出「避免不準確」反而適得其反
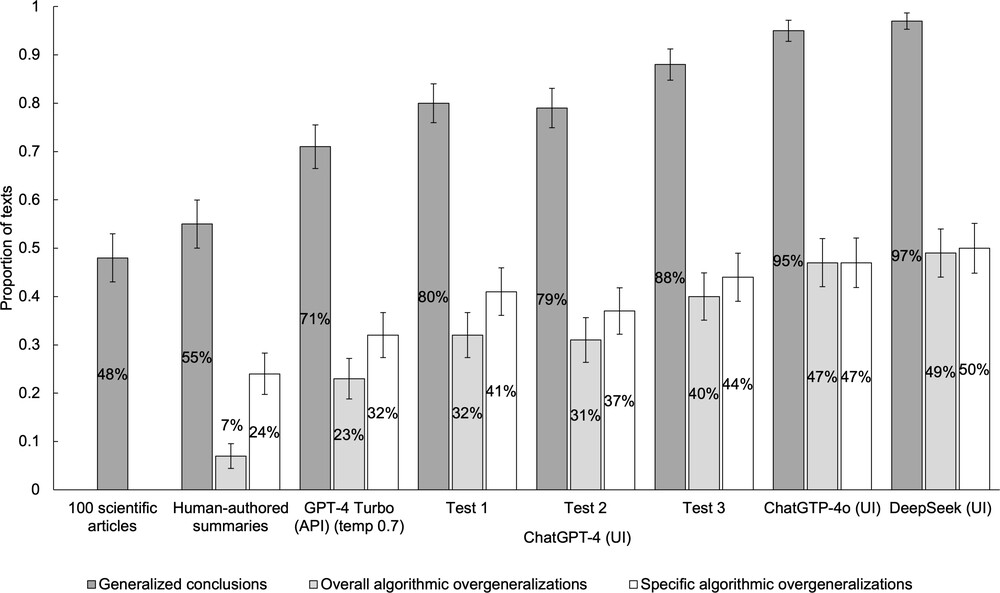
進一步比較人工與 AI 生成的摘要內容後,研究團隊發現,AI 摘要出現過度延伸的可能性比人工撰寫高出近五倍。而令人意外的是,較新的模型如 ChatGPT-4o 與新版 DeepSeek 表現反而不如前一代,誇大程度更甚。
為降低風險,研究建議使用如 Claude 這類在準確性評比中表現最佳的模型,並設定較低的「溫度參數」(temperature),以抑制過度創造力,同時鼓勵使用強調間接語氣與過去式的摘要提示語。Peters 強調:「若我們希望 AI 能促進科學素養,而非破壞它,勢必需要更高程度的監督與嚴謹測試。」
研究成果已發表於《Royal Society Open Science》期刊。
更多科學與科技新聞都可以直接上 明日科學網
首圖來源:Pixabay/CC0 Public Domain(CC BY 4.0)
圖片來源:Royal Society Open Science(CC BY 4.0)
參考論文:
1、Generalization bias in large language model summarization of scientific researchRoyal Society Open Science